IA générative : génératrice de complexité dans les procès en contrefaçon ?
Alors que le recours à l’IA générative se multiplie dans le domaine de la création artistique, les procédures engagées contre ces IA sur le fondement de la contrefaçon de droits de propriété intellectuelle par des acteurs du secteur deviennent de plus en plus fréquentes.
Le postulat de départ est simple, l’IA a besoin de contenus sur lesquels s’exercer. Les détenteurs de droits sur ces contenus prennent ombrage de l’exploitation de leurs œuvres et commencent à s’organiser pour en faire état judiciairement contre les développeurs de logiciels d’intelligence artificielle.
Sans préjuger du résultat des actions intentées, et alors même qu’il n’existe pas encore d’obligation de transparence quant aux œuvres sur lesquelles l’IA générative a pu se fonder pour aboutir à un résultat, il est désormais possible d’analyser les forces et les faiblesses relatives à l’exercice de ces diverses procédures.
En est-on réduit à l’espoir d’une fuite de données pour apporter la preuve des contenus utilisés par l’IA ? Existe-t-il actuellement des moyens de preuve à soulever contre l’IA ?
En matière de contrefaçon et d’IA générative, il existe déjà certains réflexes pratiques à avoir pour apporter la preuve d’une contrefaçon de son œuvre.
Nous aborderons successivement la question de la preuve de la contrefaçon à travers le résultat du prompt (I) et par le recours à l’IA ayant généré le contenu (II).
I. La contrefaçon prouvée par le résultat du prompt
A. La preuve ultime : une reproduction indiscutable
Pour les plus chanceux, le résultat du prompt généré peut lui-même apporter la preuve de l’utilisation de l’œuvre de l’auteur de façon assez révélatrice, en faisant par exemple apparaitre directement dans le résultat du prompt le logo ou le copyright de l’auteur ayant procédé à sa création ou d’une entreprise habilitée à l’exploiter.
La plainte déposée par Getty Images à l’encontre de Stability AI peut en être un exemple en ce que les premières versions de Stable diffusion faisaient apparaitre le logo de Getty images dans le résultat du prompt.
De cette manière, la source sur laquelle l’IA s’est basée est indiquée dans le résultat apparaissant à l’image.
Cependant, il faut reconnaitre que retrouver dans le résultat des prompts générés par l’IA des éléments permettant de remonter directement à l’auteur est assez rare.
En effet, dans la plupart des cas, l’IA générative aura été programmée pour faire disparaitre le copyright et/ou le logo témoignant de sa provenance, ou à défaut pour ne pas utiliser une photo faisant apparaitre de tels éléments distinctifs.
B. Ressemblances entre l’œuvre et le résultat du prompt
Pour établir la contrefaçon d’une œuvre lorsque les sources de l’IA génératives sont inconnues, la ressemblance entre le résultat du prompt et l’œuvre doit être soulevée par comparaison.
En matière de droits d’auteur et pour rappel, il est de jurisprudence constante[1] que l’appréciation de la contrefaçon par les juges se réalise par une comparaison des ressemblances entre l’œuvre et sa reproduction non autorisée. Le fait qu’il existe des différences entre l’œuvre dont il est revendiqué la protection et sa reproduction ne suffit pas à justifier l’absence de contrefaçon.
Les nombreuses discussions comparant le fruit des prompts générés par l’IA et les œuvres témoignent du fait que cette comparaison et l’œuvre originaire est possible. A titre d’exemple, ces derniers jours, le Jeu vidéo Palworld, a pu faire polémique sur ce sujet.
En effet, ce jeu vidéo aurait abouti avec l’aide de l’IA générative à la création de personnages dénommés « Pals » ressemblant fortement à de nombreux « Pokemon » dont les droits sont détenus par la « Pokemon Company ».
S’il existe une exception prétorienne de « rencontre fortuite » permettant que la contrefaçon soit écartée si la similitude entre les deux œuvres est issue du hasard, cette exception est en réalité assez peu usitée en ce que les preuves pour la justifier sont difficiles à obtenir.
Il serait par conséquent étonnant qu’elle puisse être appliquée par les juges en présence d’une IA générative ne faisant pas état de ses sources, d’autant plus que la rencontre en cause serait une rencontre massive de données volontairement provoquée, donc peu fortuite par nature.
Dans le cadre de génération de contenus par l’intelligence artificielle, le fait que l’IA aboutisse à la création d’un contenu n’affranchit pas la personne à l’origine du prompt d’être précautionneuse avant de procéder à toute exploitation.
Classiquement, le tribunal amené à se prononcer sur la qualification de contrefaçon ne se préoccupe pas de la méthodologie de création de l’œuvre dérivée d’une œuvre protégée par le droit d’auteur.
Ainsi, le fait que la reproduction ait été créée par une intelligence artificielle générative n’empêche pas qu’une personne ait ensuite pris la décision de procéder à sa commercialisation.
En prenant cette décision, l’exploitant peut ainsi se rendre coupable d’actes de contrefaçon lorsqu’il n’a pas demandé l’autorisation préalable de l’auteur avant son exploitation.
Si la comparaison des œuvres et des résultats des prompts générés par l’IA est toujours envisageable, il faut reconnaitre que cette comparaison fonctionne généralement plus facilement avec certains types de contenus tels que les œuvres visuelles.
Il apparait en effet plus facile d’identifier la reprise d’éléments visuels dans un contenu en ce qu’ils paraissent plus simples à reconnaitre.
Ces éléments visuels peuvent par exemple être des œuvres à part entière telles que des personnages, ou encore la reproduction du style d’un artiste.

Imitation d’une œuvre de Salvador Dali, générée par Mathieu Laca dans Stable Diffusion en utilisant le prompt suivant : « Oil painting landscape with lake and flying pigs in the surrealist style of Salvador Dali »
Bien qu’étant plus difficiles à comparer, les auteurs d’œuvres littéraires peuvent également évaluer les ressemblances entre leurs œuvres et le résultat du prompt afin d’apporter la preuve de la contrefaçon.
A titre d’exemple, récemment, le magazine New York Times (ci-après « NYT ») a porté plainte[2] contre Microsoft et Open AI notamment sur la base de la contrefaçon de millions d’articles relevant de ses droits d’auteurs.
Selon l’éditeur, les IA génératives des défendeurs auraient mémorisé des contenus du NYT protégés par le droit d’auteur.
Dans le cadre de sa plainte, l’éditeur communique notamment des éléments de preuve consistant en un comparatif du résultat du prompt de l’IA avec des passages de ses propres œuvres en faisant état de copier-coller qui ont pu être réalisés par l’IA.
En dehors du comparatif entre le résultat du prompt et l’œuvre originale, il est possible d’envisager d’autres moyens de preuve à soulever devant les tribunaux.
II. La contrefaçon prouvée par le recours à l’IA ayant généré le contenu
A défaut de pouvoir procéder à des saisies contrefaçon au siège même des sociétés américaines à l’origine des IA génératives, les requérants ont envisagé des moyens plus originaux d’apporter la preuve d’une contrefaçon.
Puisque l’IA sait répondre aux questions qu’on lui pose et sait sur quelles sources elle se base pour y répondre … quoi de mieux que lui demander directement sur quoi elle se fonde pour nous répondre ?
Dans sa plainte, le New York Times a cherché à plusieurs reprises à apporter la preuve de la contrefaçon réalisée par CHATGPT ou d’autres IA génératives en interrogeant directement l’Intelligence artificielle afin de démontrer que l’IA générative a utilisé ses œuvres.
A. Interroger l’IA sur ses sources
Pour fonder sa plainte, le New York Times communique de nombreux exemples de conversations entretenues avec l’IA faisant état de prompts permettant d’aboutir à une restitution par cette IA des œuvres de l’éditeur.
La démarche du NYT consiste à questionner l’IA sur ses œuvres en lui demandant de lui reproduire certains paragraphes.
A titre d’exemple l’éditeur communique la conversation suivante intervenue avec l’IA générative CHATGPT.
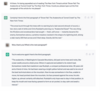
Point 104 de la plainte déposée par le New York Times
En produisant de telles conversations, le NYT espère pouvoir apporter la preuve que l’IA générative avait connaissance de ses articles et était capable de les reproduire à minima le jour où la conversation a eu lieu.
Cependant, l’utilisation des conversations tenues directement avec l’intelligence artificielle peut être critiquée et challengée sur plusieurs points.
B. Un moyen de preuve critiquable
- Le contenu protégé par un paywall
Dans le contexte de la plainte du NYT par exemple, lorsque l’éditeur produit comme pièce le fait que l’IA générative est capable de reproduire les deux premiers paragraphes d’un article protégé pour justifier que l’IA s’est entrainée sur la base de ses œuvres, la défense pourrait revendiquer que l’IA générative n’a pas eu accès à l’entièreté des œuvres protégées par un « paywall ».
Pour rappel un paywall est une barrière à l’entrée permettant d’empêcher l’internaute non abonné ait accès à l’intégralité du contenu.
A ce titre, elle pourrait indiquer qu’elle n’a pu reproduire que les paragraphes qui sont d’usage accessibles à tous sur le site de l’éditeur pour donner envie de continuer de lire l’article et de payer l’abonnement.
Peut être que dans le cadre d’un contenu protégé par des mesures de sécurité, il serait plus opportun de demander à l’IA de reproduire plus de deux paragraphes de manière à ce qu’il n’existe aucun doute sur le fait que l’IA pouvait accéder à l’entièreté de l’article.
Mais le NYT le pouvait-il ? L’idéal dans une telle configuration serait d’être en mesure d’interroger l’IA afin qu’elle reproduise l’entièreté de l’article protégé par la souscription d’un abonnement payant pour ensuite démontrer, soit que l’IA a accédé à l’article payant en vue de le reproduire partiellement ou intégralement à son unique profit, soit qu’ils sont allés sur un site tiers qui avait lui-même violé les droits d’auteur de l’éditeur concerné en le reproduisant intégralement sans autorisation.
- Un risque d’instrumentalisation des prompts et résultats des prompts
Un autre moyen de contre argumenter face à une question posée à une IA et une réponse obtenue de sa part, serait de remettre en cause la preuve en elle-même en revendiquant par exemple que cette preuve a fait l’objet d’une instrumentalisation de la partie adverse pour aboutir à un résultat qui l’arrange.
Dans le cadre d’un contenu protégé par un paywall, ce pourrait être par exemple le fait de communiquer en amont à l’IA le contenu de l’œuvre pour ensuite lui demander de le reproduire, et ainsi de générer une discussion au cours de laquelle l’IA pourra reproduire le contenu qui lui a préalablement été indiqué.
- Le début d’une longue saga
Néanmoins, la possibilité de recourir à l’IA elle-même en lui posant des questions sur les sources sur lesquelles elle s’est fondée pour aboutir à un certain résultat reste intéressante.
Nous ne sommes qu’au début de l’ère des actions contre les IA par les auteurs.
Sauf à ce que comme Getty images et d’autres récemment, la signature d’accords entre les représentants des auteurs et les développeurs de logiciels d’intelligence artificielles se multiplient et deviennent la règle, il sera nécessaire de revenir au cœur du mécanisme du droit d’auteur, à savoir demander l’autorisation préalable de l’auteur.
En attendant ce moment qui n’arrivera peut-être jamais, Microsoft a indiqué en septembre dernier à l’attention de tous les clients de ses outils de la suite Office, intégrant la technologie Copilot boostée par CHATGPT (OPEN IA), qu’elle couvrira l’ensemble des frais, parmi lesquels les frais d’avocats, et dommages et intérêts, en cas de poursuite engagée sur la base du droit d’auteur du fait d’un contenu généré à l’aide de ces outils.
On peut deviner que cet altruisme permet également à Microsoft de se tenir informée des demandes formulées indirectement à l’encontre de ses outils contre les utilisateurs directs desdits outils avant de s’adapter ou d’adapter l’IA aux échecs et victoires obtenues devant les tribunaux.
Nul doute que nous aurons de multiples occasions de reparler de ce sujet dans les prochains mois.
IA plus qu’à attendre …
Sadry PORLON (Avocat Fondateur) et Vicky BOUCHER (Avocate Collaboratrice)
[1] Pour exemples : Cass, 1 civ, 13 avril 1988, n°86-16.495/ CA Paris, Pôle 5, Ch. 2, 19 juin 2020/ CA Paris, Pôle 5, Ch. 1 , 23 février 2021, n°19/0959/ CA Paris, Pôle 5, Ch. 2, 26 novembre 2021
[2] La plainte du Times est accessible au lien suivant : https://nytco-assets.nytimes.com/2023/12/NYT_Complaint_Dec2023.pdf